February 14, 2022 | AI and NLP, Year Round Prospective HEDIS®
Real World NLP Validation for Quality Measurement
NLP is gaining traction in both payer and provider markets because it can markedly reduce the extraordinary labor costs associated with measuring healthcare quality. I’m often asked about how we validate our NLP systems for measuring quality for programs like HEDIS® and MIPS. The Astrata Team put together this FAQ to help educated buyers understand the right questions to ask. Enjoy!

Rebecca Jacobson, MD, MS, FACMI
Co-Founder, CEO, and President
How is the Accuracy of the NLP Measured?
NLP “accuracy” (often termed NLP performance) is measured using two specific performance metrics: Precision and Recall. If these names sound strange, it might be because they come from the information retrieval and computer science community. Precision is also called Positive Predictive Value (PPV), and Recall is also called Sensitivity. PPV and Sensitivity are usually more familiar to quality and measurement experts. Sometimes, you may see a third metric called the F1 (or F measure). In most cases, this is a mean of Precision and Recall, under the condition that they are weighted equally.
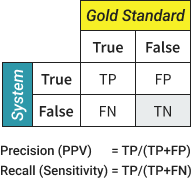
What Do Precision and Recall Actually Measure?
Precision is a measure of False Positives and Recall is a measure of False Negatives. For the measurement nerds, you’ll want to check out the definitions in Box 1 above.
Let’s get practical and imagine an NLP system that evaluates a set of EMR charts for members who are on your gap list. The NLP system classifies these cases as either Hits or True Gaps – a binary choice. A Hit represents a case where there is sufficient evidence in the clinical notes to determine that the member is already compliant with a specific measure despite the absence of a claim, and a True Gap represents a case where the documentation suggests that the member is truly non-compliant.
Precision tells you the percentage of cases labeled as Hits by the NLP system, that are in fact Hits. If this number is less than 1 (or 100%) it means that there are False Positives – cases where the NLP system calls something a Hit but an abstractor would disagree and call it a True Gap. As precision increases, abstractors do less unnecessary work, and the risk of reporting data incorrectly goes down.
Recall tells you the percentage of cases labeled as True Gaps by the NLP system, that are in fact True Gaps. If this number is less than 1 (or 100%) it means that there are False Negatives – cases where the NLP system calls something a True Gap but an abstractor would disagree and call it a Hit. As recall increases, there is less risk that you miss cases that could count towards your overall compliance rate.
We’ll discuss more about how you know whether something really is a Hit or Not Hit when we discuss Gold Standards.
Do Precision and Recall Help Me Determine Product Value?
Yes and no. High Precision and Recall are important prerequisites, but they are not sufficient to quantify value.
Why Can’t I Use Precision and Recall as a Proxy for Product Value?
Precision and recall are very important in validating an NLP system, but they don’t tell you about the value of the product. That’s because the value of the product depends on what impact the product makes on key performance indicators such as efficiency. An NLP system could be perfectly accurate (Precision = 1, Recall = 1), and yet the use of the product provides no immediate value over the standard practice. Imagine a measure where 100% of your gap list is compliant, the population is small, and it is simple and fast to abstract each gap in the EMR. NLP may provide no value in triaging cases, and no value in speeding abstraction.
How is the Value of an NLP Product Measured?
This is a much harder question because it depends on the task that the NLP is being used for. In the case of quality measurement, we can imagine several aspects of value including (1) the reduction of labor costs, (2) the ability to move medical record review to the measurement year (often called prospective or year-round HEDIS review), and (3) the potential impact on measure rates.
How Do I Match the Right Metric to the Value Proposition?
You should definitely keep in mind that different uses of NLP require different ways to quantify the value produced. For example, if your NLP system is doing a last-pass quality review after your abstractors are done, then you are probably most interested in the potential increase in your rates by finding missed compliant cases. On the other hand, if your system is a first-pass triage system (like Astrata’s Chart Review) then reducing your labor costs might be your most important value proposition. In fact, when NLP is used for prospective HEDIS®, most payers are trying to keep costs down as they transition to prospective HEDIS® review while the HEDIS® sample is de-emphasized and eventually discontinued.
The Number of Hits or Exclusions Closed by the Abstractor is Divided by the Total Time.
Multiple by which NLP-powered abstraction increases efficiency over the standard practice.
For the task of prospective HEDIS®, we usually want to calculate two things. First, we want to know how quickly the medical record abstractors can close hits and exclusions – the gap closures per unit of time. We call that Hits per Hour. That’s different than knowing how many cases abstractors can review. In a prospective review, you won’t expect to look at every case. Your goal is to focus abstraction on the cases that increase your reported rates to get them closer to your true rates. Only hits and exclusions are of value here. Second, we want to compare this value to what you can achieve using your standard processes. We call that ratio the Speed Up Factor.
For example, let’s say that your abstractors are doing prospective HEDIS® by direct EMR access and review; they might be able to close 5 gaps per hour. With NLP, perhaps they can close 20 gaps per hour, a speed-up of 4x. In practice, NLP produces a range of speed-up factors depending on the measure, and the population. In many cases, these speed-up factors can be remarkably high, which makes prospective, population-based medical record review feasible and cost-effective.
That May Be True, but What if Precision and Recall are Low? Does that Say Anything About Product Value?
While high Precision and Recall do not necessarily equate to high value, low precision and recall definitely hint at reduced value. At a Precision of 0.5 (or 50%), you are essentially tossing a coin as to whether the member is a Hit or True Gap. Your abstractors would be looking at many more negative cases. This will reduce the efficiency gain, producing a decrease in closures per hour as well as a reduced speed-up factor.
How are Precision and Recall Usually Measured?
While there are several ways to measure NLP performance, the most rigorous way involves the use of independent, expert annotators to perform the same task that the NLP system is trying to perform. The humans make their judgments first, and then the system is then measured against this “gold standard”.
In our example system above, we would ask multiple trained medical record reviewers to review a set of medical records and determine whether it is a Hit or True Gap. These human judgments are based on annotation guidelines that derive from the HEDIS® measure definitions. And we call that expert-labeled set a Gold Standard. Once the dataset has been labeled in this way, we run the NLP system on the same data. We then determine where the NLP agrees with the gold standard that a case was a Hit (True Positive) or a True Gap (True Negatives) and where the NLP system incorrectly labeled something a Hit (False Positive) or a True Gap (False Negative). These values are then used to calculate Precision and Recall as shown in Box 1. One benefit of a gold standard is that you are able to measure both Precision and Recall.
Is Recall Important in Prospective HEDIS®? There is No Way I Can Close All the Positive Cases!
There is no doubt that prospective, population-based HEDIS® is very different than the yearly HEDIS® sample. For one thing, the number of cases worked in prospective review seems astronomical. That’s where triage becomes essential, and it’s one of the great advantages of NLP systems to cut down your work dramatically. But it also has implications for your performance metrics. Your team may have so many hits and exclusions to close, that they never actually get to the end. In this case, precision becomes the critical metric to watch.
What Happens if NLP Becomes a Method for Generating Standard Supplemental Data? Does this Impact the Performance Measures I Should Care About?
Currently, NLP can only be used in an assistive mode to drive reductions in labor or to find missing gap closures. But NLP performance is becoming quite good and now rivals human performance. If NLP systems were to become a method for generating standard supplemental data, then the key performance metric to pay attention to would be Precision. That’s because we want the quality of any data being reported to be very, very high. As we transition to automation, we can expect that some fraction of cases will continue to be reviewed by human abstractors. These might include the more difficult and nuanced cases or cases that NLP systems cannot classify with high confidence. During that time, systems that present their low-confidence cases to humans will not have to worry as much about recall. As the NLP systems improve, we can expect more cases to be automated and fewer cases to be read by humans. At this point recall becomes much more important to ensure that we do not underreport measure rates.
Do You Have to Use a Gold Standard? Can You Measure NLP Performance in Other Ways?
There are other options besides using a gold standard which can still give you a lot of useful information. For example, expert review of NLP output can help you determine Precision (but not recall). When using expert review, you provide a set of cases that an NLP system has already classified and ask one or more experts to tell you whether it was right or not. Unlike a gold standard, this method does not start with a random set of cases labeled independently by the system and the experts. An advantage of expert review is that it can often be done at a much lower cost than developing a gold standard. Some people argue that expert review is more biased than using a gold standard. However, with the right type of experts and the right review workflow, it is possible to minimize the bias of these evaluations. One disadvantage of using the expert review method is that this method can usually only tell you about Precision, not Recall. If this method sounds familiar – it is extremely similar to Primary Source Verification (PSV). In fact, PSV could be a useful, widely understood work process for measuring the validity of an NLP system.
Another type of evaluation is to monitor the percent agreement as real-world abstractors use the NLP output. This is the percentage of times that your abstractors agree with the NLP system when it serves up a hit or exclusion for them to close. Percent agreement is usually a good estimate of Precision in the wild, as long as you keep in mind that medical record abstractors can make mistakes too.
Are Precision and Recall Constants for a Given System, or Do They Change Over Time and Across Data?
Precision and Recall are definitely NOT constants, and you should be wary of anyone who tells you that their system will always produce the same performance metrics on new data. NLP systems are known to have portability issues, meaning that when they are moved to a new setting, performance degrades. There are many reasons for this (I feel another blog coming on), but the important thing to understand is that you won’t necessarily know the performance of your data unless you or someone else measures it.
Does that mean that Measuring the System Against One Gold Standard Won’t Necessarily Predict the Performance of My Data?
Correct. The ability to generalize from performance metrics obtained on one gold standard to your environment will depend on how similar the data is in your environment when compared with what’s in that gold standard. Although it’s tempting to try to come up with a dataset that is so diverse that it represents all data – it is simply not practical or likely to work. Measurement of NLP performance really has to be a local phenomenon.
Will NLP Performance and Value Metrics Vary by Measure?
Precision and Recall will absolutely vary by measure within a given population, and so will the value metrics like hits closed per hour and speed-up factors. It’s important to make sure that evaluations are being done for each measure that you plan to use.
What is the Unit of Analysis for NLP Performance and Why Does it Matter?
In our description above, we’ve treated everything as a binary choice made at the member level. Simple is good for blogging! But NLP performance evaluation is actually much more complex and can be done at several different levels or “units of analysis”. In addition to the member level, we can evaluate at the document level or at the mention level. When we evaluate a document as the unit of analysis, we are making our judgments about what’s right or wrong for each document. This means that if there are two or three individual statements that could be used as HEDIS® evidence, it doesn’t matter if the system finds one of them or all of them. When we evaluate with mention as the unit of analysis, we are making our judgments about what’s right or wrong for each individual mention of HEDIS® evidence within a document. Mention level analysis is the most rigorous, but also the most expensive and time-consuming. On the other hand, member-level analysis can be too coarse in most cases. When measuring NLP Performance for Quality, the Document is actually the unit of analysis that fits quality measurement tasks most closely. Astrata measures its NLP performance metrics (precision and recall) at the Document level but tracks statistics such as % agreement at the member level.