April 23, 2021 | AI and NLP, Patents
Proving It: How Astrata Evaluates and Improves NLP Accuracy
If you’re evaluating NLP vendors, you’ll want to ask how your vendor evaluates and improves NLP accuracy. With over a decade of experience developing NLP systems for clinical environments, Astrata’s NLP teams understand that the value of NLP to your Quality operations depends on the highest possible accuracy.
So what questions should you be asking when you evaluate an NLP vendor? We think these three are critical:
-
- How do you measure NLP accuracy?
- Given NLP’s portability issues, how will you evaluate and improve the accuracy of your system in my specific organization and setting?
- How will your system learn and adapt as it’s embedded in our workflow?
Let’s step through how we answer these three big questions at Astrata.

Rebecca Jacobson, MD, MS, FACMI
Co-Founder, CEO, and President
1) How We Measure Accuracy at Astrata
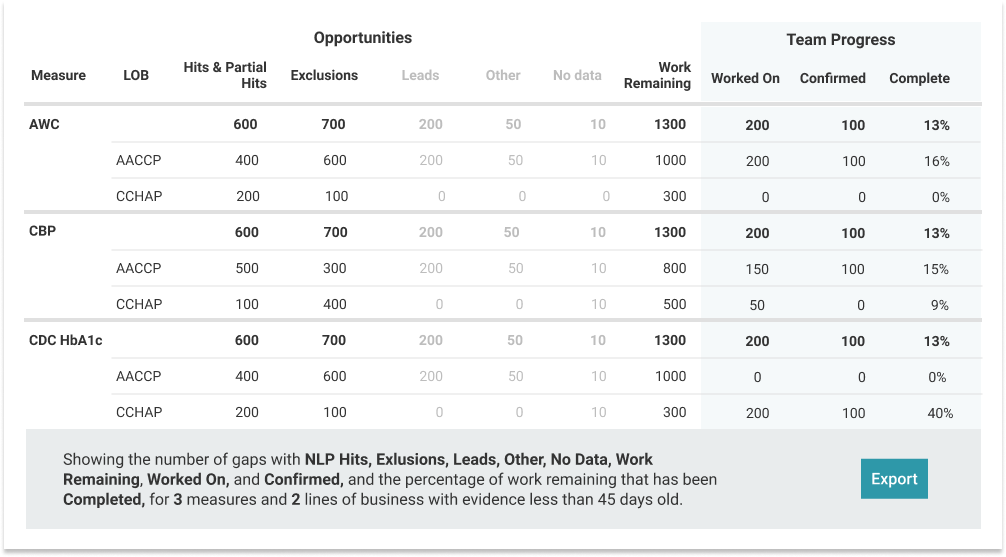
We want to introduce you first to Astrata’s measure development team – a cross-disciplinary unit that includes clinically-trained quality experts, computational linguists, and terminology specialists. When we develop a measure, we begin by developing a gold standard for that measure. Gold standards are composed of real clinical documents labeled by our clinical quality experts, based on the current year’s HEDIS® spec. We measure false positives and false negatives by comparing the NLP’s results to the gold standard — effectively, comparing the NLP to how trained clinical abstractors would review the same charts.

When our measure development team creates a new measure or adapts a measure based on the next year’s HEDIS® specification, we compare it to the gold standard to establish precision, recall, and F1 baseline statistics for every measure, focusing more on precision because that metric aligns best with the goals of prospective year-round HEDIS®.
- Precision (a.k.a. Positive Predictive Value) measures the fraction of members we call Hits or Exclusions that are in fact Hits or Exclusions. (A Hit means NLP has found clinical evidence of HEDIS compliance sufficient to close a member gap; an Exclusion means NLP has found clinical evidence of exclusion sufficient to close the gap.) Precision is a measure of False Positives; it tells you how much extra/unnecessary work your abstractors would need to do in examining records that the NLP indicates have enough evidence for closure, but in fact, do not. Every False Positive wastes your team’s time, and our measure development team is laser-focused on finding False Positives and adjusting the NLP to reduce them.
- Recall (a.k.a. Sensitivity) measures the fraction of members that are truly Hits or Exclusions that our system will label as Hits or Exclusions. Recall is a measure of False Negatives, and it tells you how many gap closures you might leave on the table because they are never surfaced to your abstraction team. Astrata’s measure development team and NLP engineers seek out and adjust the NLP system to reduce false negatives.
- F1 We also use a balanced measure called F1 that equally weights False Positives and False Negatives. That can be helpful if you care equally about False Positives and False Negatives.
Almost all of Astrata’s measures have a baseline precision of 88%, and many have a baseline precision of>95%. We share with you the accuracy of every measure we deploy.
2) How we evaluate the accuracy of Astrata’s NLP in your organization and setting
It’s a well-known limitation of NLP that when systems move to a new setting, their accuracy goes down. Why is this? There are many factors, such as regional and local differences in EMR data-entry requirements, but the important thing is to understand that it happens and confirm that your vendor will be able to make adjustments to increase NLP accuracy in your specific setting, quickly and efficiently. These adjustments may be needed only in your environment. Does your NLP vendor’s system scale in a way that makes specific, targeted, timely adjustments possible for each of their individual clients? Astrata’s NLP does.
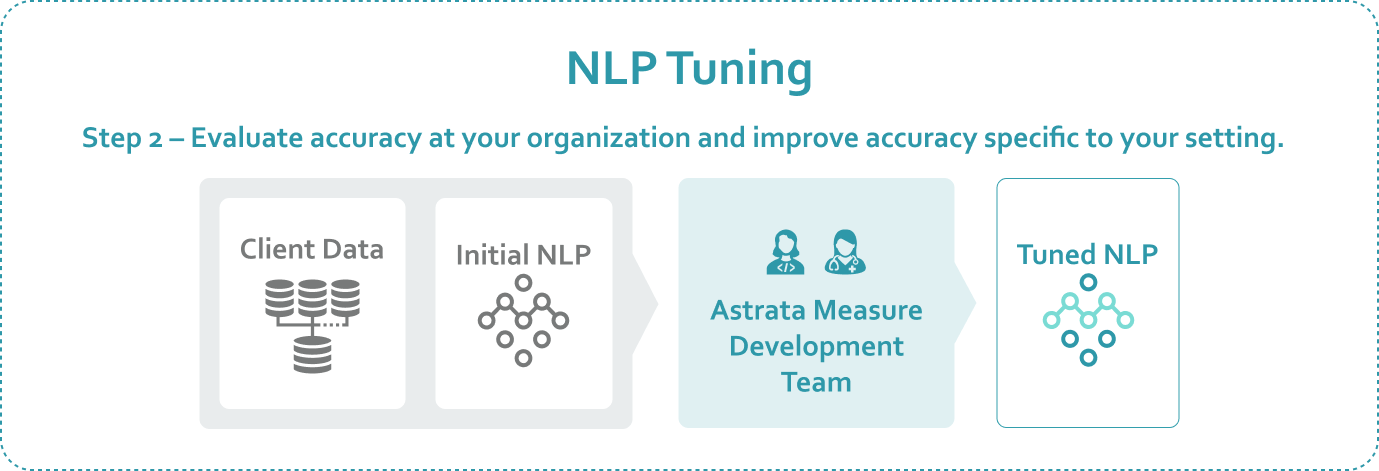
As part of every engagement, Astrata evaluates our measures against your data and modifies the software so that it does a better job in your environment. Astrata’s NLP Insights is designed from the ground up to easily and quickly adjust how the NLP behaves, making it possible to tailor the system for your organization.
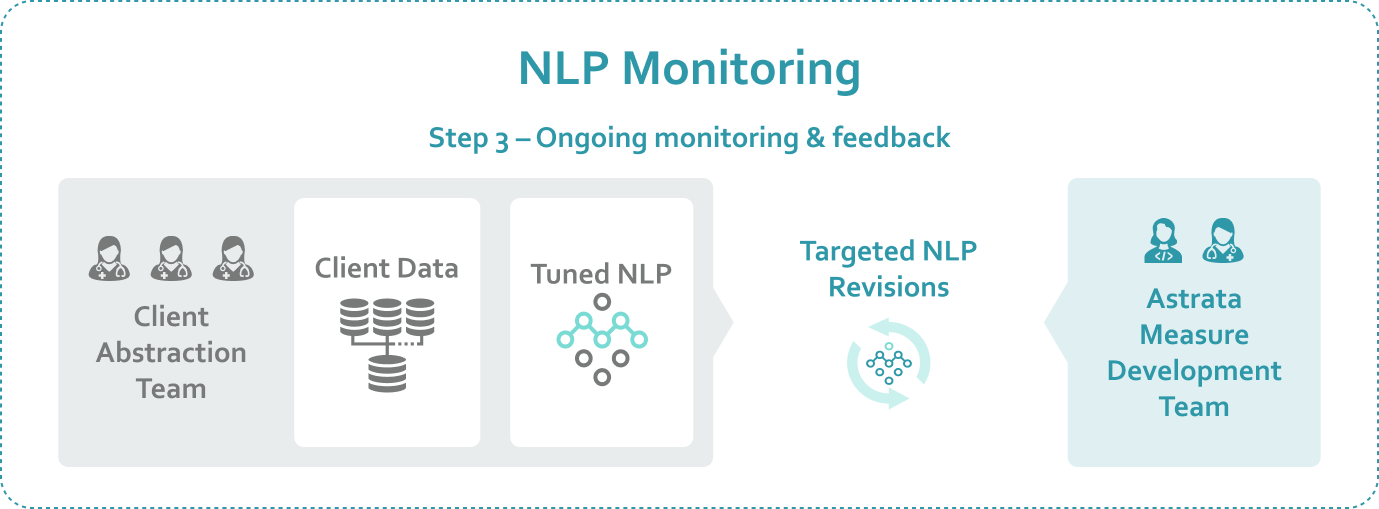
(3) How Astrata’s System Learns and Changes as it’s Embedded in Your Workflows
Our improvements don’t stop when we deploy the software. We monitor our NLP accuracy by analyzing every case where your abstractors disagree with the NLP’s results. And we use every disagreement to improve. But we’ll also share something that might surprise you: when we look at disagreements with abstractors, we find that our system is right over half the time. When the measure development team receives multiple examples of the same disagreement, the cases are sent to our independent, NCQA–certified auditor, and in some cases, we send a PCS question to NCQA for clarification. The responses are incorporated into our NLP system or shared with our customers to provide feedback to the abstractors.
Astrata’s Chart Review also includes tools for abstractors to provide direct feedback to the measure development team; abstractors can flag errors or ask questions using our one–click feedback form. Chart Review also gives you self-serve dashboards and reports to see how accurate the NLP is, and our develop team share what modifications will be made when something goes wrong.